Matchmaking Simulator
1. Overview
PGOS provides a simulator to verify a ruleset, which takes a Fake Player Dataset and ruleset name as input, and simulates the progress of matchmaking. It differs from real scene matchmaking in that it runs matchmaking in a single thread, while the real matchmaking service can handle loads of matchmaking tickets simultaneously.
The matchmaking simulator does the following jobs:
- Simulate real scene matchmaking in a single-thread model.
- Sort out the statistical data based on the simulated matchmaking results.
- Export matchmaking results as a
csvfile for developers to do data post-processing tasks.
By using a matchmaking simulator, developers can know the tendencies of the ruleset they write, and what kinds of matchmaking tickets will be successfully matched, and those kinds of tickets that will time out due to the difficulty in finding close tickets to them.
2. Create Simulation Case
Two parameters are required to create a simulation case:
- A ruleset.
- A fake player dataset that matches the player attributes defined in the ruleset above.
After a simulation case is created, it will show up in the list, in a status of Running. The simulation case will keep running until the server finds no more tickets that can be matched together according to the constraints of the ruleset, or the running time reaches the limit, then the status will turn into Completed.
The time limit of a simulation case is the max waitTimeSeconds defined in the expansions section of the ruleset, plus 30 seconds, which should be enough for most cases. But if the fake player dataset is too large or the constraints of the ruleset are too strict, most of these tickets will time out.
3. Inspect Simulation Result
3.1 Create a Demo Ruleset
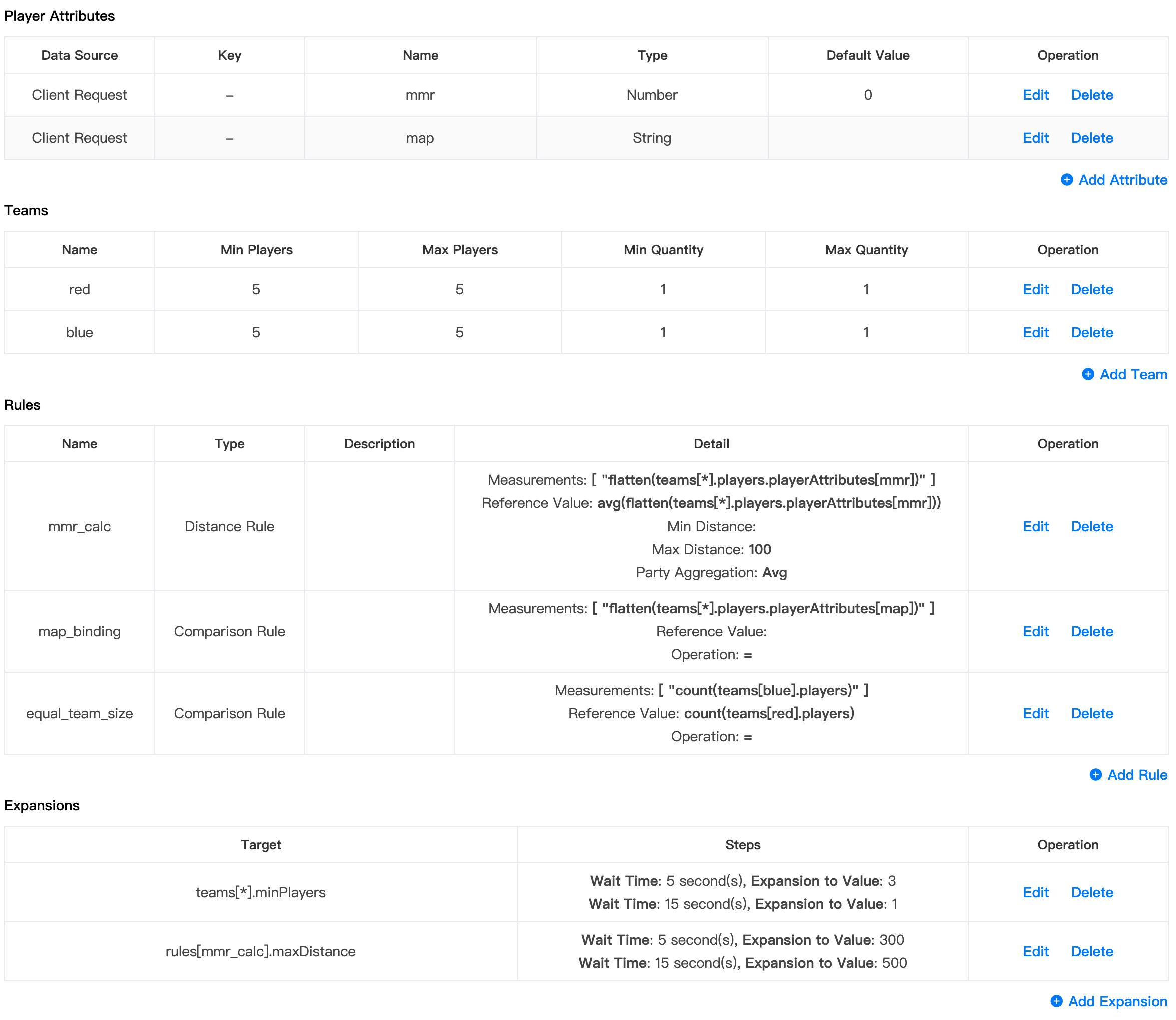
Let's take this 5v5 ruleset as an example:
- Two attributes:
mmrandmapare defined. - Two teams, 5v5 by default, relaxed to 1v1 if no tickets are matched after 15 seconds.
- A distance rule that refers to the
mmrof players in a battle, which limits the max distance of themmrto 100, and is relaxed to 500 after 15 seconds. - A comparison rule that refers
map, which will group players who chooses the samemapin a battle. - A comparison rule that uses the
countfunction to ensure two teams have the same number of players.
3.2 Create a Fake Player Dataset
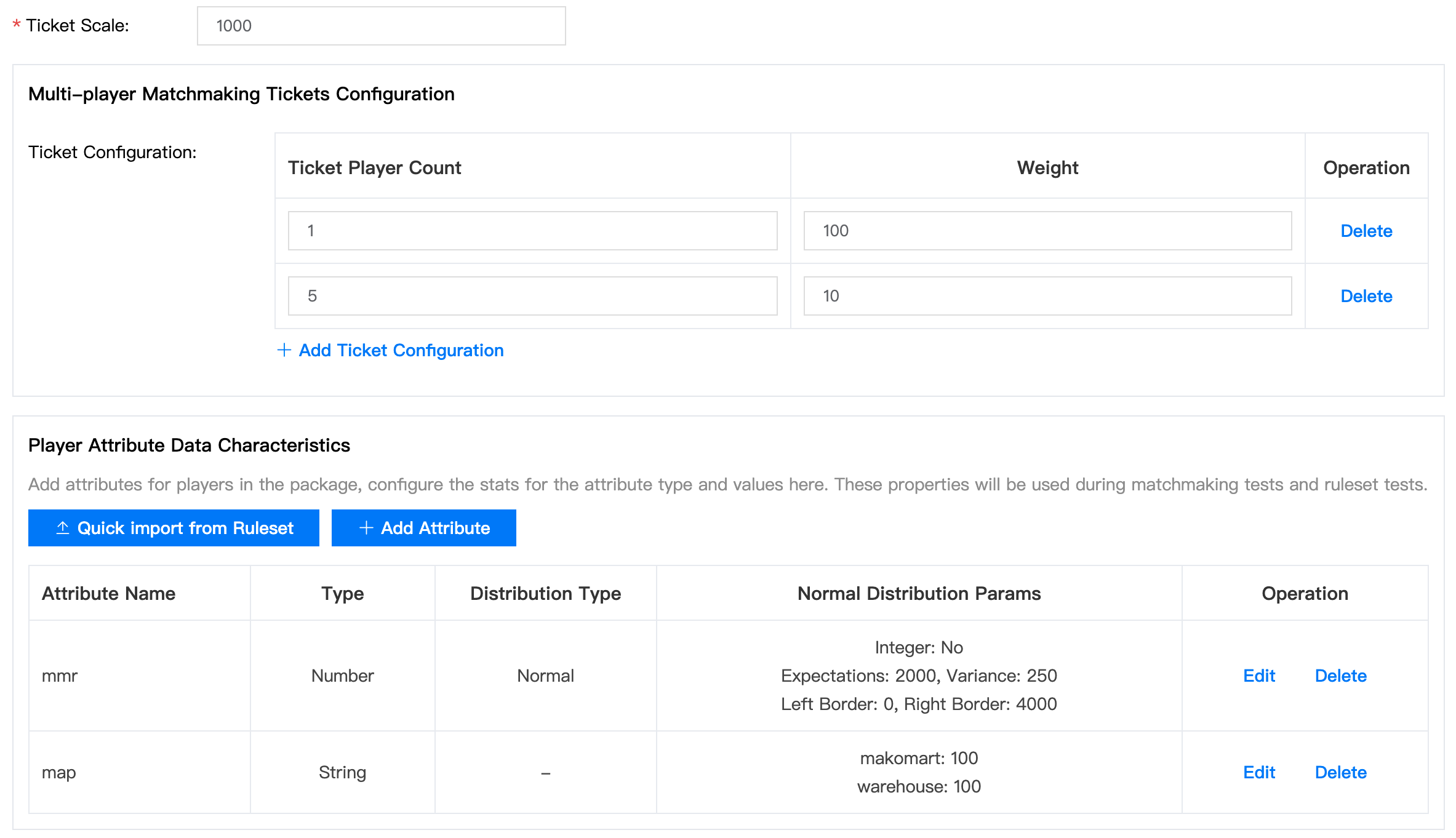
Next, we create a fake player dataset that contains 1000 matchmaking tickets:
- Let's mix some solo tickets with 5-player tickets, and make the ratio to be 100:10
- Quickly import attribute definitions from ruleset
mmrcommonly meets normal distribution, let's makeavgto be 2000 andstddevto be 250, so that some tickets will have to wait for the rules to be expanded to find matched tickets : )maphas two enums: makomart and warehouse, the ratio is 100:100
3.3 Fire the Simulation
Now we start the simulation using the ruleset and fake player dataset above. One or multiple rulesets can be selected for simulation. When multiple rulesets are chosen, the simulator will follow the strategy of Multiple Rulesets to run.
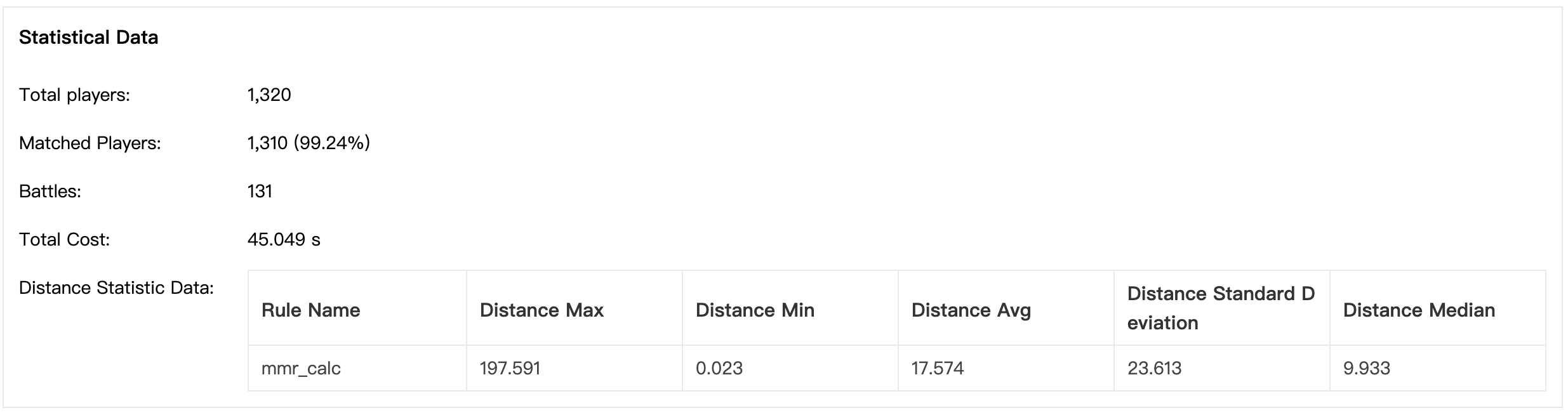
The running status lasts 45 seconds, 990 of 1000 tickets are matched, and 131 battles are generated.

The distance rule statistics data is at the bottom of the detail page, which shows the distance value in statistics methods. This data helps developers to evaluate the effect of the distance rule.
4. Data Post Processing
The matchmaking result can be exported as csv file.
The first six columns are predefined: player_id, ticket_id, battle_id, team, reput_count, elapsed_ms, followed by the player attributes, each as a separate column.
player_id,ticket_id,battle_id,team,reput_count,elapsed_ms,mmr,map
player-713,ticket-545,6a1449ba76e5dc22cae44b94a436d8cd,red,0,587,1786.863027,warehouse
player-714,ticket-545,6a1449ba76e5dc22cae44b94a436d8cd,red,0,587,2241.119114,warehouse
player-715,ticket-545,6a1449ba76e5dc22cae44b94a436d8cd,red,0,587,2103.677505,warehouse
player-716,ticket-545,6a1449ba76e5dc22cae44b94a436d8cd,red,0,587,1785.970212,warehouse
player-717,ticket-545,6a1449ba76e5dc22cae44b94a436d8cd,red,0,587,2182.409426,warehouse
player-116,ticket-84,6a1449ba76e5dc22cae44b94a436d8cd,blue,0,588,1920.060106,warehouse
player-698,ticket-530,6a1449ba76e5dc22cae44b94a436d8cd,blue,0,587,1920.138307,warehouse
player-724,ticket-552,6a1449ba76e5dc22cae44b94a436d8cd,blue,1,587,1921.581073,warehouse
player-1303,ticket-991,6a1449ba76e5dc22cae44b94a436d8cd,blue,1,585,1921.651445,warehouse
player-413,ticket-321,6a1449ba76e5dc22cae44b94a436d8cd,blue,1,588,1922.898499,warehouse
player-711,ticket-543,a16ad3d0dff1aaa5e47826e1ad2d27eb,red,1,748,1523.588655,makomart
player-929,ticket-701,a16ad3d0dff1aaa5e47826e1ad2d27eb,red,0,747,1434.742317,makomart
player-1166,ticket-886,a16ad3d0dff1aaa5e47826e1ad2d27eb,red,0,747,1435.582740,makomart
player-1180,ticket-900,a16ad3d0dff1aaa5e47826e1ad2d27eb,red,0,747,1444.452618,makomart
player-632,ticket-484,a16ad3d0dff1aaa5e47826e1ad2d27eb,red,0,748,1444.593095,makomart
player-126,ticket-94,a16ad3d0dff1aaa5e47826e1ad2d27eb,blue,0,749,1377.014577,makomart
player-599,ticket-459,a16ad3d0dff1aaa5e47826e1ad2d27eb,blue,0,748,1395.522473,makomart
player-358,ticket-278,a16ad3d0dff1aaa5e47826e1ad2d27eb,blue,0,749,1421.479525,makomart
player-1116,ticket-844,a16ad3d0dff1aaa5e47826e1ad2d27eb,blue,0,747,1449.029000,makomart
player-712,ticket-544,a16ad3d0dff1aaa5e47826e1ad2d27eb,blue,0,748,1458.602227,makomart
...
reput_count is an internal parameter in the matchmaking system. In order to expose as many details inside the black box as possible to help developers understand the ruleset they write, reput_count is exported.
In a matchmaking system, tickets are kept in a ticket pool for the matchmaker to retrieve on demand to find matches. The matchmaker pops out the ticket with the lowest reput_count as the first ticket in an empty match, and then tries to fill the remaining slots by using the filters figured out with the deduction result of the rules. If no matches are found, finally, the reput_count of these tickets is increased and put back in the ticket pool, and waits for the next try.
So the easy-to-match tickets will have relatively low reput_count and vice versa. And some of the timedout tickets will have a zero value of reput_count. Normally, most of the tickets will have a 0~5 reput_count range, and the average value is below 1.
There are two recommended methods to deal with a high reput_count situation:
- Relax the limitations of rules step by step to lower the difficulty of finding qualified matches.
- Create a ruleset by modes to let different targeted players use different rulesets.
elapsed_ms means the time in milliseconds that the ticket takes to find matches. But since the simulation tool runs in a single thread, the data does not represent real performance when the ruleset is put online.
The elapsed_ms data can show the time node at which some tickets are not matched until the ruleset expansion happens. It can also be analyzed by drawing histograms to balance the efficiency and precision of a ruleset.
By utilizing the CSV data, developers can:
- Create histograms of matchmaking costs and player attribute distributions.
- Do research on clustering algorithms based on matchmaking data.
- Optimize ruleset design by reducing the overall time costs.
Contact us if you have any advice on using the matchmaking simulator.