匹配模拟器
1. 概述
PGOS提供了一个用于验证规则集的模拟器,它以虚拟玩家数据集和规则集名称作为输入,并模拟匹配过程。它与实际场景的匹配不同之处在于它在单线程中运行匹配,而实际的匹配服务可以同时处理大量的匹配请求。
匹配模拟器执行以下任务:
- 在单线程模型中模拟实际场景的匹配。
- 根据模拟匹配结果整理统计数据。
- 将匹配结果导出为
csv文件,供开发人员进行数据后处理任务。
通过使用匹配模拟器,开发人员可以了解他们编写的规则集的趋势,哪些类型的匹配请求会成功匹配,以及哪些类型的请求会因难以找到相近的请求而超时。
2. 创建模拟案例
创建模拟案例需要两个参数:
- 规则集
- 与上述规则集中定义的玩家属性相匹配的模拟玩家数据集
创建模拟案例后,它将出现在列表中,状态为运行中。模拟案例将持续运行,直到服务器发现根据规则集的约束条件无法再匹配到更多票据,或运行时间达到限制,此时状态将变为已完成。
模拟案例的时间限制是规则集的expansions部分中定义的最大waitTimeSeconds加上30秒,这对大多数情况来说应该足够。但如果模拟玩家数据集太大或规则集的约束条件太严格,大部分票据将会超时。
3. 检查模拟结果
3.1 创建示例规则集
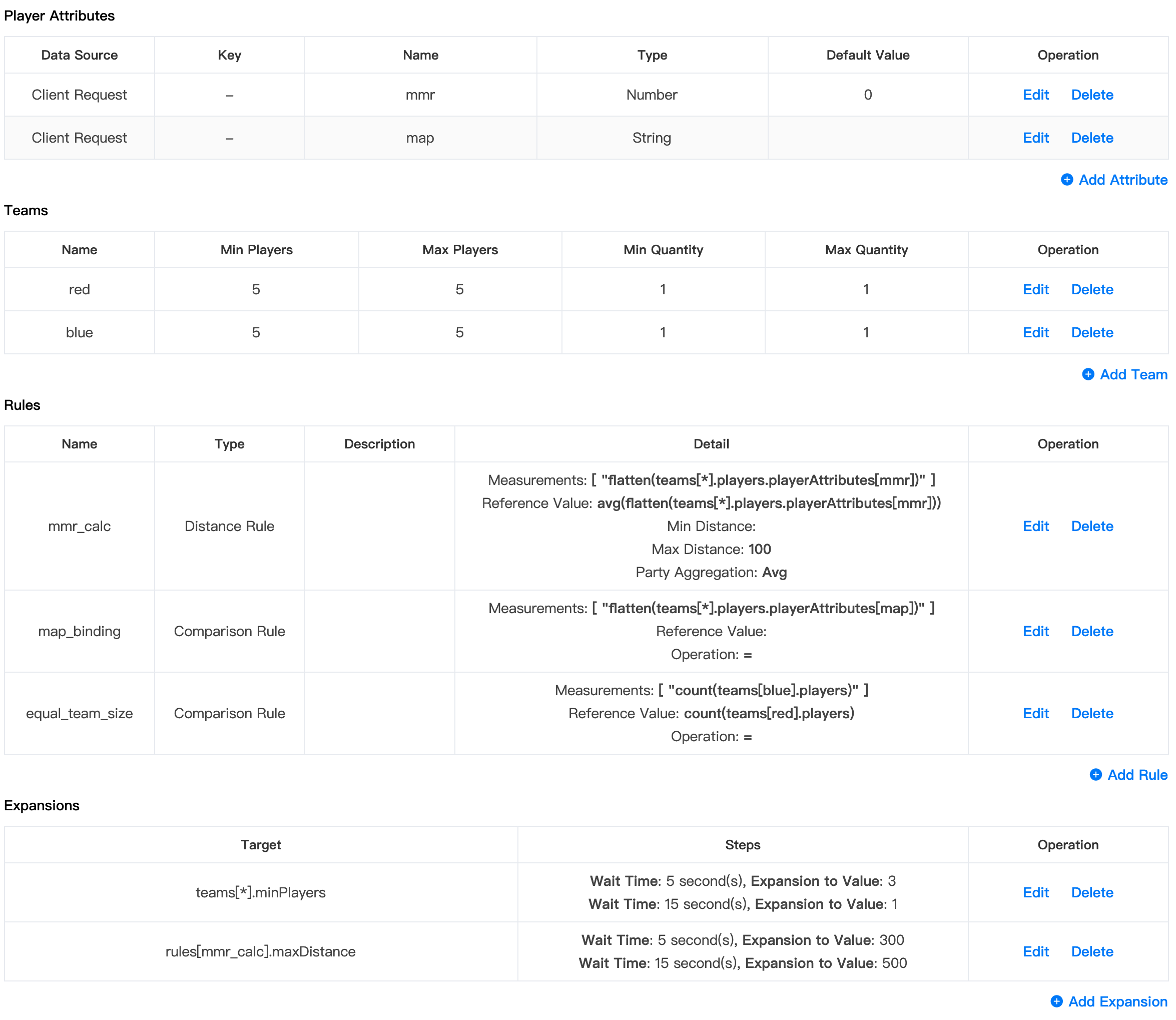
让我们以这个5v5规则集为例:
- 定义了两个属性:
mmr和map。 - 两个队伍,默认为5v5,如果15秒后没有匹配到门票则放宽至1v1。
- 一个引用对战中玩家
mmr的距离规则,限制mmr的最大距离为100,15秒后放宽至500。 - 一个引用
map的比较规则,将选择相同map的玩家分到同一对战中。 - 一个使用
count函数的比较规则,确保两个队伍拥有相同数量的玩家。
3.2 创建模拟玩家数据集
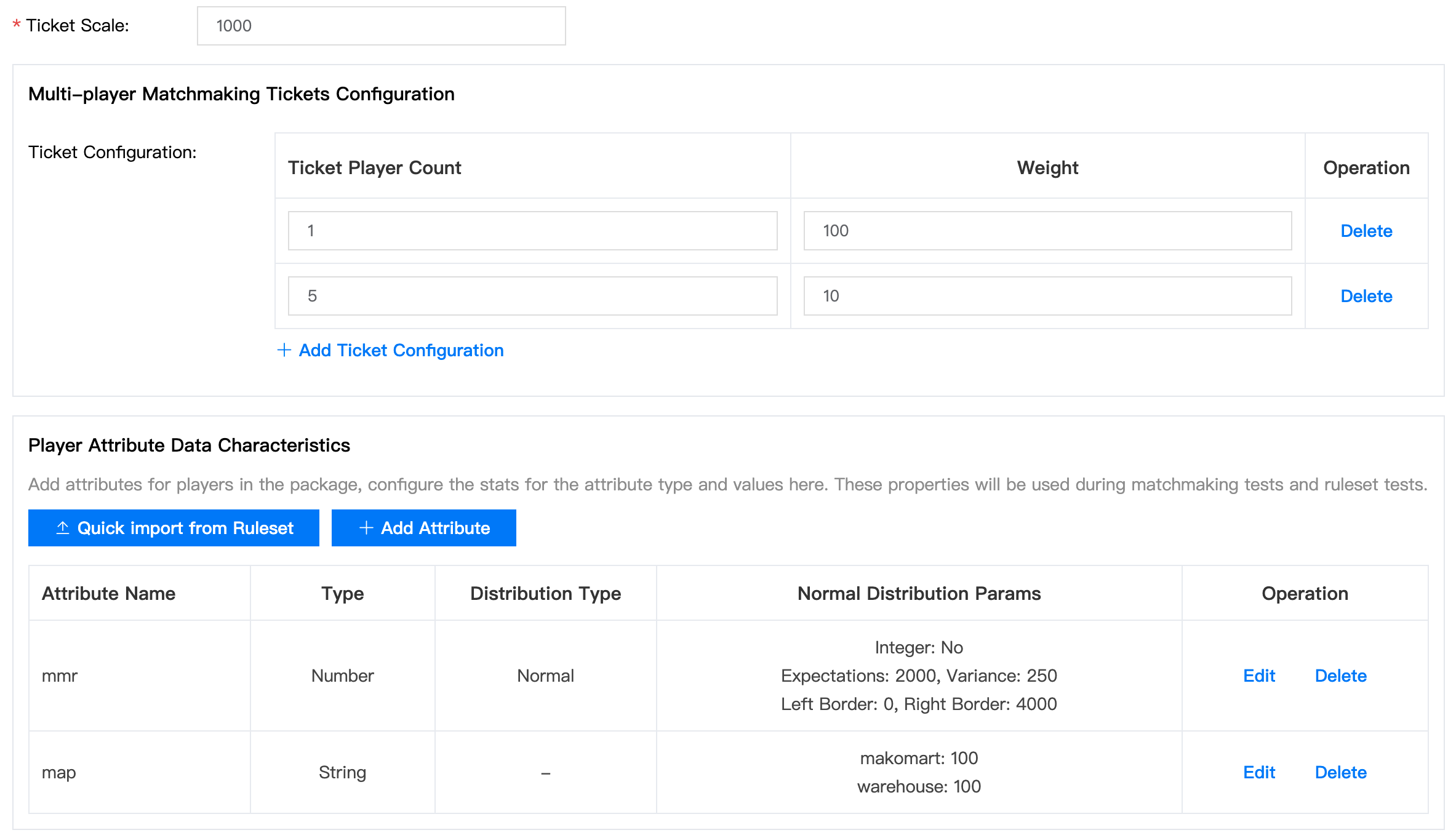
接下来我们创建一个包含1000个匹配请求的模拟玩家数据集:
让我们混合单人请求和5人组请求,比例设为100:10
从规则集中快速导入属性定义
mmr通常符合正态分布,让我们将avg设为2000,stddev设为250,这样一些请求需要等待规则扩展才能找到匹配的请求 : )map有两个枚举值:makomart和warehouse,比例为100:100
3.3 运行模拟
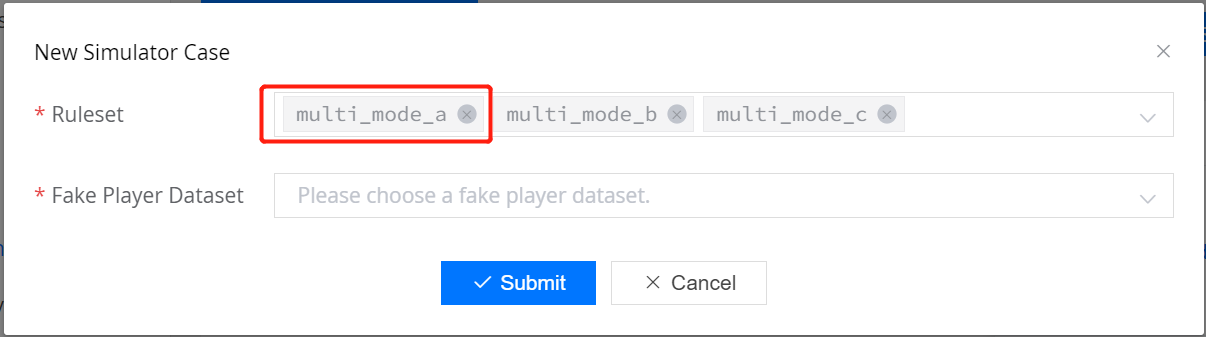
现在我们使用上述规则集和模拟玩家数据开始模拟。可以选择一个或多个规则集进行模拟。当选择多个规则集时,模拟器将遵循多规则集策略来运行。
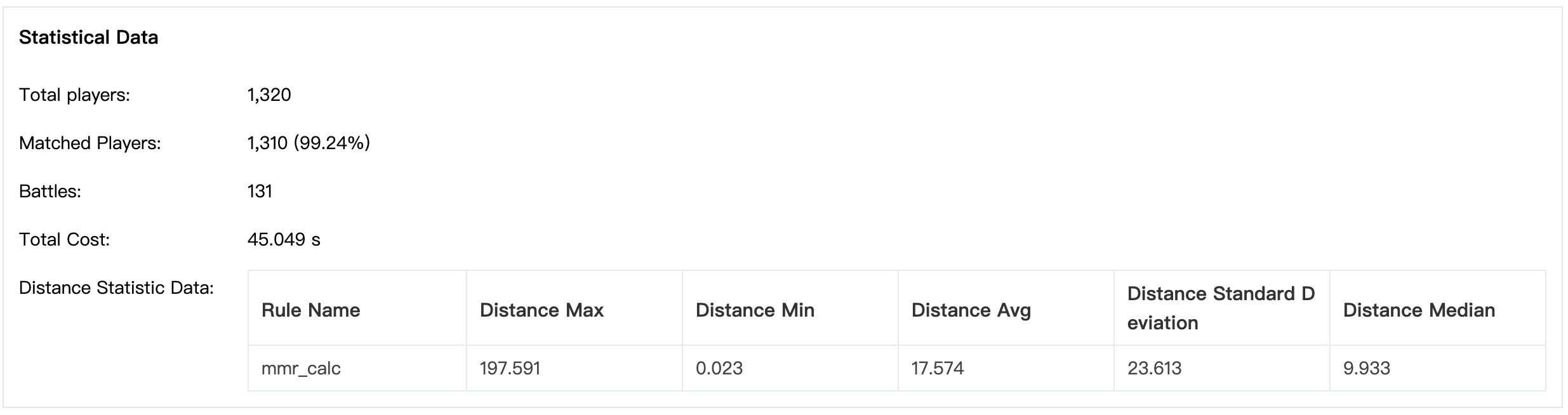
运行状态持续45秒,1000张门票中有990张匹配成功,生成了131场对战。

距离规则统计数据位于详情页底部,显示了各种统计方法下的距离值。这些数据可帮助开发人员评估距离规则的效果。
4. 数据后处理
匹配结果可以导出为csv文件。
前六列是预定义的:player_id、ticket_id、battle_id、team、reput_count、elapsed_ms,后面是玩家属性,每个属性单独一列。
player_id,ticket_id,battle_id,team,reput_count,elapsed_ms,mmr,map
player-713,ticket-545,6a1449ba76e5dc22cae44b94a436d8cd,red,0,587,1786.863027,warehouse
player-714,ticket-545,6a1449ba76e5dc22cae44b94a436d8cd,red,0,587,2241.119114,warehouse
player-715,ticket-545,6a1449ba76e5dc22cae44b94a436d8cd,red,0,587,2103.677505,warehouse
player-716,ticket-545,6a1449ba76e5dc22cae44b94a436d8cd,red,0,587,1785.970212,warehouse
player-717,ticket-545,6a1449ba76e5dc22cae44b94a436d8cd,red,0,587,2182.409426,warehouse
player-116,ticket-84,6a1449ba76e5dc22cae44b94a436d8cd,blue,0,588,1920.060106,warehouse
player-698,ticket-530,6a1449ba76e5dc22cae44b94a436d8cd,blue,0,587,1920.138307,warehouse
player-724,ticket-552,6a1449ba76e5dc22cae44b94a436d8cd,blue,1,587,1921.581073,warehouse
player-1303,ticket-991,6a1449ba76e5dc22cae44b94a436d8cd,blue,1,585,1921.651445,warehouse
player-413,ticket-321,6a1449ba76e5dc22cae44b94a436d8cd,blue,1,588,1922.898499,warehouse
player-711,ticket-543,a16ad3d0dff1aaa5e47826e1ad2d27eb,red,1,748,1523.588655,makomart
player-929,ticket-701,a16ad3d0dff1aaa5e47826e1ad2d27eb,red,0,747,1434.742317,makomart
player-1166,ticket-886,a16ad3d0dff1aaa5e47826e1ad2d27eb,red,0,747,1435.582740,makomart
player-1180,ticket-900,a16ad3d0dff1aaa5e47826e1ad2d27eb,red,0,747,1444.452618,makomart
player-632,ticket-484,a16ad3d0dff1aaa5e47826e1ad2d27eb,red,0,748,1444.593095,makomart
player-126,ticket-94,a16ad3d0dff1aaa5e47826e1ad2d27eb,blue,0,749,1377.014577,makomart
player-599,ticket-459,a16ad3d0dff1aaa5e47826e1ad2d27eb,blue,0,748,1395.522473,makomart
player-358,ticket-278,a16ad3d0dff1aaa5e47826e1ad2d27eb,blue,0,749,1421.479525,makomart
player-1116,ticket-844,a16ad3d0dff1aaa5e47826e1ad2d27eb,blue,0,747,1449.029000,makomart
player-712,ticket-544,a16ad3d0dff1aaa5e47826e1ad2d27eb,blue,0,748,1458.602227,makomart
...
reput_count 是匹配系统的一个内部参数,为了尽可能暴露黑匣子内部的细节,帮助开发者理解自己编写的规则,reput_count 被导出。
在匹配系统中,票证保存在票证池中,匹配器可以根据需要检索以找到匹配对象。匹配器会弹出具有最低 reput_count 的票证作为空匹配中的第一张票证,然后尝试使用根据规则的推导结果找出的过滤器来填充剩余的空位。如果最终没有找到匹配对象,则将这些票证的 reput_count 增加并放回票证池,等待下一次尝试。
因此,容易匹配的票证将具有相对较低的 reput_count,反之亦然。并且一些超时的票证的 reput_count 值将为零。一般情况下,大部分 ticket 的 reput_count 范围在 0~5 之间,平均值小于 1。
对于 reput_count 过高的情况,建议使用两种方法:
- 逐步放宽规则限制,降低匹配难度。
- 分模式创建规则集,让不同目标玩家使用不同的规则集。
elapsed_ms 表示 ticket 匹配时间,单位为毫秒。但由于模拟工具是单线程运行的,该数据并不代表规则集上线时的真实表现。
elapsed_ms 数据可以显示在规则集扩展前,部分 ticket 未匹配的时间节点。也可以通过绘制柱状图进行分析,以平衡规则集的效率和精度。
通过利用 csv 数据,开发者可以:
- 绘制匹配成本和玩家属性分布的柱状图。
- 基于匹配数据研究聚类算法。
- 优化规则集设计,降低总体时间成本。
如果您对使用匹配模拟器有任何建议,请联系我们。